Regret定义
n轮游戏,参与者每次选择一个action,获取reward。参与者每次选择action时都要参考之前的reward,来使n轮的reward累积最大化,或者是让regret最小化,regret的定义为:
Rn=na∈Amaxμa−E[t=1∑nXt]
算法
At={(tmodk)+1argmaxiμ^i(mk) if t⩽mk if t>mk
引理一
引入
Ta=t=1∑nX{At=a},Δa=μ∗−μa
可以将regret函数改写成
Rn=a∈A∑t=1∑nE[(μ∗−Xt)X{At=a}]=a∈A∑t=1∑nX{At=a}Δa=a∈A∑ΔaE(Ta(n))
对于上式的第二步的处理,需要考虑条件期望
===E[(μ∗−Xt)X{At=a}∣At]X{At=a}E[(μ∗−Xt)∣At]X{At=a}(μ∗−μa)X{At=a}Δa
引理二
对于 X服从 σ−subgaussian分布,有
P(X⩾ε)⩽e−λσ22ε
亚高斯分布定义:
∀λ∈RE(eλx)⩽e2λ2σ2
对于 ∀λ>0,
P(X⩾ϵ)=P(eλX⩾eλϵ)⩽eλϵE(eλX) (Markov’s inequality) ⩽e2λϵλ2σ2 (Def. of subgaussianity) ⩽e−λσ22ε
取 λ=ε4,即可得到
引理三
对于 X服从 σ−subgaussian分布
E(X)=0,V(X)≤σ2,cX∼∣c∣⋅σ− subguassian
X1,X2独立,服从 σ1−subgaussian 和σ2−subgaussian分布
X1+X2∼σ12+σ22− subguassian
对于 Xi−μ服从 σ−subgaussian分布
P(μ^⩾μ+ε)⩽e−2σ2nε2
=⩽P(μ^−μ⩾ε)P(n1i=1∑n(Xi−μ)⩾ε)e−2ε2σ2n
对于上式的最后一步的处理,需要考虑
n1i=1∑n(Xi−μ)∼nnσ2− subguassian
Regret分析
Rn⩽mi=1∑kΔi+(n−mk)i=1∑kΔiexp(−4mΔi2)
假设 μ1=μ∗,根据引理一
Rn=i=1∑kΔiE[Ti(n)]
前mk轮选择一定
E[Ti(n)]=m+(n−mk)P(Amk+1=i)⩽m+(n−mk)P(μ^i(mk)⩾jFimaxμ^j(mk))⩽m+(n−mk)P(μ^i(mk)⩾μ^1(mk))⩽m+(n−mk)P(μ^i(mk)−μi−(μ^1(mk)−μ1)⩾Δi)⩽m+(n−mk)exp(−4mΔi2)
对于上式的最后一步的处理,需要考虑引理三及
μ^i(mk)−μi−(μ^1(mk)−μ1)∼m1+m1− subguassian
如果k=2
Rn⩽mΔ+(n−2m)Δexp(−4mΔ2)⩽mΔ+nΔexp(−4mΔ2)
给出一个m的选取
m=max{1,[Δ24log(4nΔ2)]}
Regret的上界为
Rn⩽min{nΔ,Δ+Δ4(1+max{0,log(4nΔ2)})}Rn⩽Δ+Cn
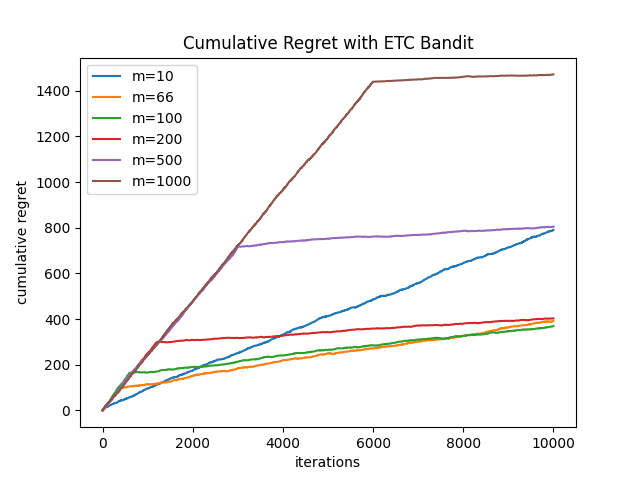
运行结果